이번 포스트에서는 python에서 excel을 다루기위해 openpyxl 라이브러리에 대해서 알아보도록 하겠습니다.
아래와 같은 내용을 알아보도록 하겠습니다.
01 excel의 구조
02 openpyxl 튜토리얼: excel 생성, sheet 및 cell 접근 및 value
excel의 구조
python으로 excel을 다루기 전에 대상이 되는 excel에 대해서 알아봅시다. 엑셀은 아래의 구조를 가지고 이를 통해 openpyxl에서는 엑셀을 다루게 됩니다.
1. 엑셀파일(book)
2. 시트(sheet)
3. 행(row)
4. 열(column)
5. 셀(cell)
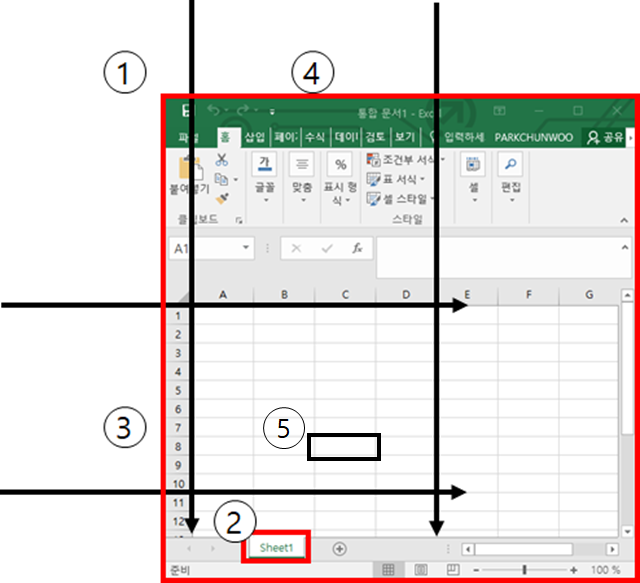
openpyxl 튜토리얼
# In 1: workbook 및 sheet 선택
from openpyxl import Workbook
wb=Workbook() # 엑셀 book 생성
ws=wb.active # 활성 worksheet 선택
# In 2: sheet 다루기
ws.title="default" # shhet 이름 변경
ws1=wb.create_sheet("test1") # 새로운 sheet를 생성합니다.
ws2=wb.create_sheet("test2",0) # sheet의 위치를 제일 첫번째 자리로 지정합니다.
ws3=wb.create_sheet("test3",-1) # sheet의 위치를 끝에서 두번째 자리로 지정합니다.
ws2.sheet_properties.tabColor="1072BA" # sheet 탭 색 변경; RRGGBB
# In 3: workbook sheet 확인
print(wb.sheetnames)
# 출력결과: ['test2', 'default', 'test3', 'test1']
for sheet in wb: # 이와 같이 loop 시켜서 출력할 수도 있습니다.
print(sheet.title)
# In 4: cell 다루기 - 접근 및 value
ws['A2']="A2Value"
# ws.cell() 함수 ws.cell(row=2, column=1, value="A2Value")를 통해 동일한 결과를 얻을 수 있습니다.
a3=ws['A3']
a3.value="A3Value"
tuple(ws.rows) # ws.cloumns를 사용하면 열 기준 결과물을 얻을 수 있습니다.
print("A3 key :",a3)
print("A3 value : ",a3.value)
# In 5: ws.iter_rows나 cols를 활용하여 접근하기
# ws.iter_rows나 cols를 활용하면 특정 범위의 셀에 접근할 수 있습니다.
for row in ws.iter_rows(min_row=1, max_col=3):
for cell in row:
print(cell)
for row in ws.iter_rows(min_row=1, max_col=3, values_only=True): # values_onely를 이용하여 value를 확인할 수 있습니다.
for cell in row:
print(cell)
# In 6: range()함수를 이용해서 작성해보기
for row in range(1,3):
for col in range(2,3):
ws.cell(column=col, row=row, value=("col: "+str(col)+"/ row: "+str(row)))
print(ws.cell(row,col).value)
# In 7: 파일 저장하기
wb.save('test.xlsx')
In 1 > 새로운 workbook와 sheet를 생성합니다. 만약 기존에 생성되어 있는 excel 파일 및 sheet을 활용하고자 한다면 load_workbook 메소드를 이용한 코드를 통해 파일을 불러올 수 있습니다.
from openpyxl import load_workbook
wb=load_workbook('/파일이름.xlsx')
ws=wb['시트명']
In 2 > excel 파일은 book의 형태이며, book은 적어도 한 개 이상의 sheet를 가지게 되며 default 네임은 sheet1이 됩니다. In 2까지의 수행으로 아래와 같은 sheet 결과물을 확인할 수 있습니다.

In 4 >
worksheet의 각 cell은 worksheet가 메모리에 적재될 때 포함되지 않고 개별 cell에 접근할 때 비로소 적재되는 것을 확인할 수 있습니다. 따라서 ln 4 수행 후 tuple(ws.rows)와 ln 5 수행 후 tuple(ws.rows)의 결과값이 달라지는 것을 확인할 수 있습니다.
# In 4
>>> tuple(ws.rows)
((<Cell 'default'.A1>,), (<Cell 'default'.A2>,), (<Cell 'default'.A3>,))
# In 5
>>> tuple(ws.rows)
((<Cell 'default'.A1>, <Cell 'default'.B1>, <Cell 'default'.C1>), (<Cell 'default'.A2>, <Cell 'default'.B2>, <Cell 'default'.C2>), (<Cell 'default'.A3>, <Cell 'default'.B3>, <Cell 'default'.C3>))
엑셀을 사용하다 보면 범위의 형태로 cell을 선택하고 다뤄야 할일이 있을 수 있습니다. 이 때 슬라이싱을 사용해 접근할 수도 있습니다.
>>> colC= ws['A'] # columns A에 접근
>>> cell_range=ws['B1':'B3'] # cell B1:B3에 접근
>>> row10 =ws[10] # 10번째 row에 접근
>>> row_range=ws[1:10] # 1번째 row에서부터 10번째 row까지 접근
In 7 > 핸들링하던 workbook을 저장할 때는 wb.save() 함수를 사용할 수 있습니다. 이 때, wb.save(/경로/파일명.xlsx)로 저장할 수 있으며, 변수값을 활용할 수 있습니다.
최종 결과물을 확인해봅니다.
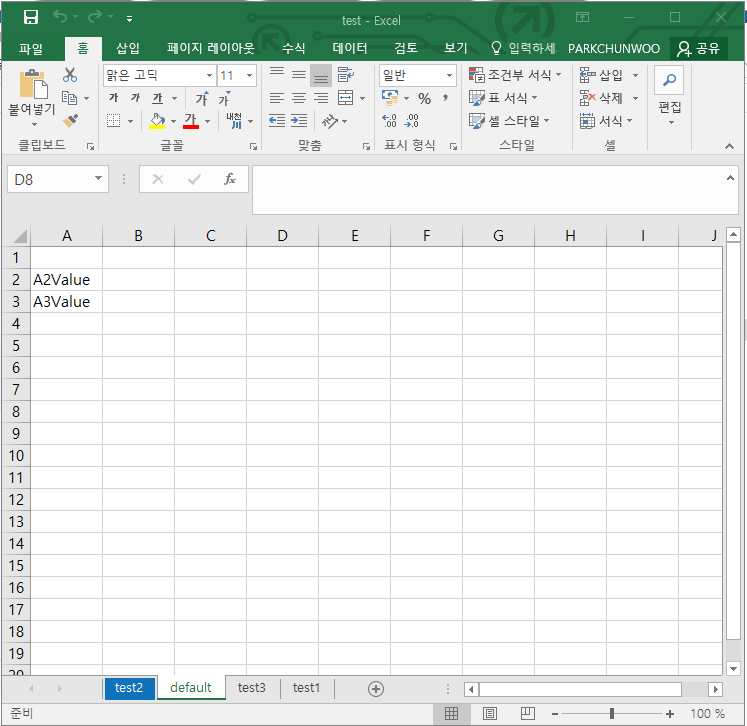
이상 excel을 다루기 위한 openpyxl 라이브러리를 알아봤습니다.
이어서 실제 웹 상에 존재하는 데이터를 수집하여 excel로 작업하는 방법에 대해서 알아보도록 하겠습니다. urllib 및 BeautifulSoup를 활용하여 웹 데이터를 분석하는 방법이 궁금하신 분은 아래의 링크를 이용해 주시기 바랍니다.
[Python] openpyxl로 excel 다루기02 (urllib, BeautifulSoup)
이번 포스트에서는 python에서 실제 웹 상에 존재하는 데이터들을 excel로 저장하는 방법에 대해서 알아보도록 하겠습니다. 따라서 아래의 세가지 라이브러리를 활용해보도록 하겠습니다. 01 urllib
todaysgoal.tistory.com
참고문헌
OpenPyXL. openpyxl.readthedocs.io/en/stable/tutorial.html#. 인용일: 2021.02.18.
'ITStudy > Python' 카테고리의 다른 글
| [python] BeautifulSoup를 통한 크롤링 차단 시 해결 방법 (0) | 2021.02.22 |
|---|---|
| [Python] openpyxl로 excel 다루기02 (urllib, BeautifulSoup) (0) | 2021.02.19 |
| [Python] BeautifulSoup로 웹 데이터 분석 with DART (0) | 2021.02.01 |
| [Python] urllib로 웹 데이터 핸들링 with DART (0) | 2021.01.31 |
| import와 from의 차이[Python] (0) | 2021.01.29 |